For over a decade, centralised data architectures-data warehouses, data lakes, and lakehouses have formed the backbone of enterprise analytics. They promised a “single source of truth,” governance, and efficiency. Yet by 2026, many organisations are finding that these systems are no longer fit for purpose. The scale, speed, and diversity of modern data have exposed fundamental limitations in centralisation.
Enter data mesh not as a trend, but as a structural shift in how organisations think about data ownership, architecture, and value creation.
The Problem with Centralised Data Architectures
Bottlenecks in Data Ownership
Centralised architectures rely heavily on a small number of data engineering teams to ingest, process, and serve data across the organisation. This creates a persistent bottleneck. As data demand grows, these teams become overwhelmed, delaying delivery and reducing responsiveness to business needs.
In 2026, when real-time insights are often critical to competitiveness, waiting weeks or even days for data pipelines to be updated is no longer acceptable.
Scaling Challenges in Distributed Environments
Modern enterprises operate across multi-cloud, hybrid environments, and edge systems. Centralised architectures struggle to scale across such distributed ecosystems. Moving large volumes of data into a single repository introduces latency, cost, and operational complexity.
Data gravity compounds the issue: the more data you centralise, the harder and more expensive it becomes to move or replicate it.
Loss of Domain Context
When data is centralised, it is often stripped of the business context that gives it meaning. Data engineers who are distant from the source domain may misinterpret requirements or design inefficient transformations.
This results in datasets that are technically correct but operationally irrelevant, undermining trust and usability across the organisation.
Governance vs Agility Trade-off
Centralised systems tend to prioritise governance, often at the expense of agility. Strict schemas, rigid pipelines, and approval layers slow down innovation. While governance remains essential, especially with increasing regulatory scrutiny, it cannot come at the cost of adaptability.
In 2026, organisations require architectures that can balance both without compromise.
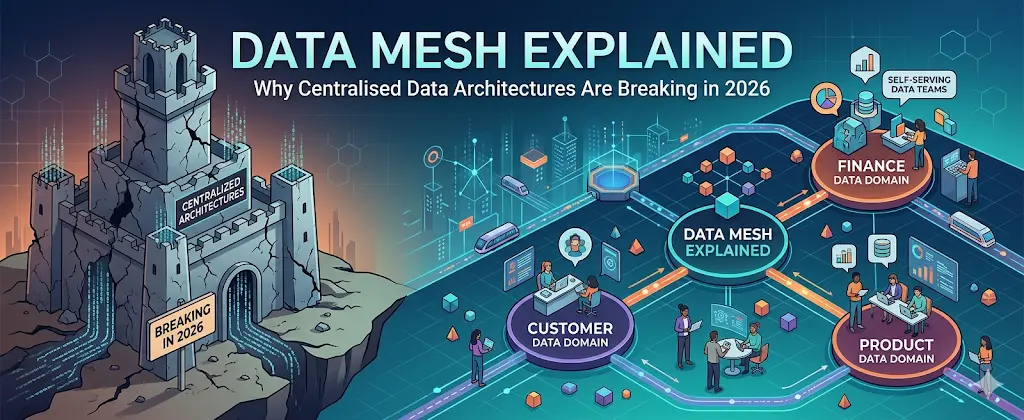
What Is Data Mesh?
A Paradigm Shift, Not Just a Technology
Data mesh is an architectural and organisational approach that decentralises data ownership. Instead of a central team managing all data, domain-oriented teams take responsibility for their own data as a product.
This shift is underpinned by four key principles:
- Domain-oriented ownership
- Data as a product
- Self-serve data infrastructure
- Federated computational governance
Unlike traditional architectures, data mesh is less about tools and more about operating models.
Core Principles of Data Mesh
Domain-Oriented Ownership
Each business domain, such as finance, marketing, or operations, owns its data pipelines and datasets. These teams understand their data best and are therefore best positioned to manage, maintain, and evolve it.
This eliminates reliance on central teams and accelerates data delivery.
Data as a Product
In a data mesh, datasets are treated as products with defined consumers, quality standards, SLAs, and documentation. This product mindset ensures that data is discoverable, reliable, and usable.
Teams are accountable not just for producing data, but for ensuring it delivers value.
Self-Serve Data Platform
To prevent chaos, organisations must provide a robust self-serve platform. This includes tooling for data ingestion, transformation, storage, and governance.
The platform abstracts complexity, allowing domain teams to focus on business logic rather than infrastructure management.
Federated Computational Governance
Governance in a data mesh is decentralised but standardised. Policies are defined centrally but enforced automatically through technology.
This ensures compliance and consistency without creating bottlenecks.
Why Data Mesh Is Gaining Traction in 2026
Explosion of Data Sources
From IoT devices to SaaS platforms and AI-driven applications, data sources have multiplied dramatically. Centralised systems cannot ingest and process this diversity efficiently.
Data mesh allows data to remain closer to its source while still being accessible across the organisation.
Rise of AI and Real-Time Analytics
AI workloads demand high-quality, domain-specific data delivered in near real time. Centralised pipelines often fail to meet these latency and contextual requirements.
By decentralising data ownership, data mesh enables faster iteration and more accurate models.
Organisational Scalability
As organisations grow, central teams cannot scale linearly. Data mesh distributes responsibility, enabling parallel development and reducing dependency chains.
This aligns with modern DevOps and platform engineering practices.
Challenges and Misconceptions
Not a Silver Bullet
Data mesh is not an instant fix. It requires significant cultural and organisational change. Without proper governance and platform support, decentralisation can lead to fragmentation and inconsistency.
Requires a Mature Data Culture
Organisations must invest in data literacy and accountability. Domain teams need the skills and mindset to manage data effectively.
Platform Complexity
Building a self-serve data platform is non-trivial. It requires investment in automation, standardisation, and tooling.
However, this complexity is often offset by long-term gains in scalability and agility.
Centralised vs Data Mesh: A Practical Comparison
Centralised architectures excel in environments with relatively stable data requirements and limited scale. They provide strong governance and consistency but struggle with agility and scalability.
Data mesh, by contrast, thrives in dynamic, large-scale environments. It distributes ownership, improves responsiveness, and aligns data more closely with business needs, but requires stronger coordination and cultural alignment.
The Future: Hybrid Approaches
In practice, many organisations in 2026 are adopting hybrid models. Core data assets may remain centralised, while domain-specific datasets are decentralised.
This allows organisations to retain the benefits of central governance while gaining the flexibility of a data mesh.
Conclusion: From Control to Enablement
The failure of centralised data architectures is not due to poor design, but changing realities. The scale, speed, and complexity of modern data ecosystems demand a new approach.
Data mesh represents a shift from control to enablement from a centralised authority to distributed responsibility. For organisations willing to embrace this change, it offers a path to scalable, agile, and context-rich data architectures fit for the demands of 2026 and beyond.